MOMENTUM: Hierarchical Context Injection for
Multi-Modal Agent Orchestration in Enterprise Content Generation
Google @ NeurIPS 2025
Google Cloud · Mountain View, California
Above: a 360° race car whose sponsor logos and text remain pixel-accurate across every generated view. These aren’t placeholder graphics: MOMENTUM’s Cross-Team Sponsorship Model gives the agent live, read-only access to each sponsor’s official logos, colors, and brand assets as they evolve in their own team profiles—ensuring generated content always reflects the latest approved identity, not a stale copy. This is enterprise-grade multi-tenant context at work. MOMENTUM solves the critical problem of context loss in tool-augmented language models by injecting six hierarchical context layers—brand voice, user identity, team intelligence, media, and settings—through every tool invocation across text, image (Imagen), and video (Veo) generation. The result: a 30-day campaign’s final asset is as semantically faithful to a brand’s identity as its first. Built on Google ADK with 22 tools, persistent dual-scope memory via Vertex AI, and validated at 94% accuracy across 225 tests.

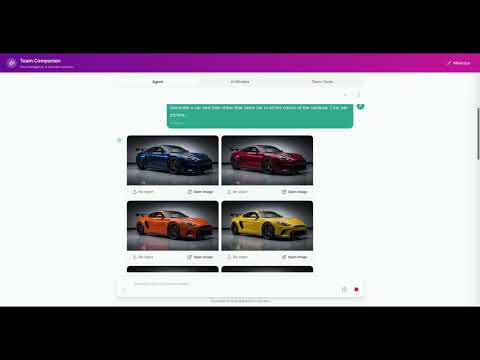
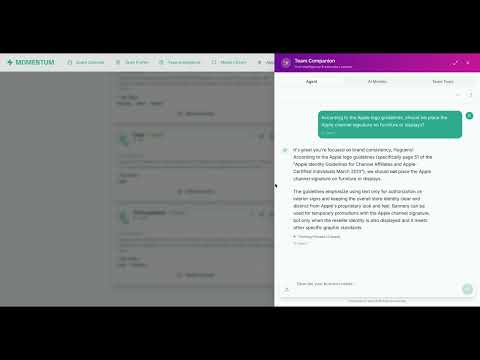
Abstract
We present MOMENTUM, a production multi-modal agent architecture built on the Google Agent Development Kit (ADK) that addresses a fundamental limitation in tool-augmented language models: the systematic loss of contextual information across heterogeneous tool invocations. Our system introduces a Hierarchical Context Injection mechanism that propagates six distinct context layers—brand, user, individual identity, settings, media, and team—through all 22 tool invocations via Python’s contextvars module, ensuring semantic preservation across text generation, image synthesis, video creation, web search, and media retrieval modalities.
Our principal contributions are: (1) a formalized context injection architecture with O(1) context access complexity per tool invocation, eliminating the linear degradation observed in sequential agent pipelines; (2) a Team Intelligence Pipeline that synthesizes structured knowledge representations (“Brand Soul”) from heterogeneous artifacts using confidence-weighted extraction and deduplication at 0.85 cosine similarity threshold; (3) Dual-Scope Memory Banks implementing organizational and individual persistent memory via Vertex AI Agent Engine with Firestore fallback and provenance-tracked deletion cascades; (4) Individual Identity Context Blending using a 70/20/10 weighted composition of personal profile, team intelligence mentions, and organizational voice; and (5) a Cross-Team Sponsorship Model enabling unidirectional read-only context observation between organizational tenants without context contamination.
Evaluation on a 225-test suite across 9 categories yields 100% tool selection accuracy (n=60), 94% overall accuracy, pass@5 = 100%, and a stability score of 99.26%. The system is validated by 2,854 automated tests (2,315 frontend, 539 backend) across 400 test files spanning 73 test modules.
MOMENTUM NotebookLM
System Architecture
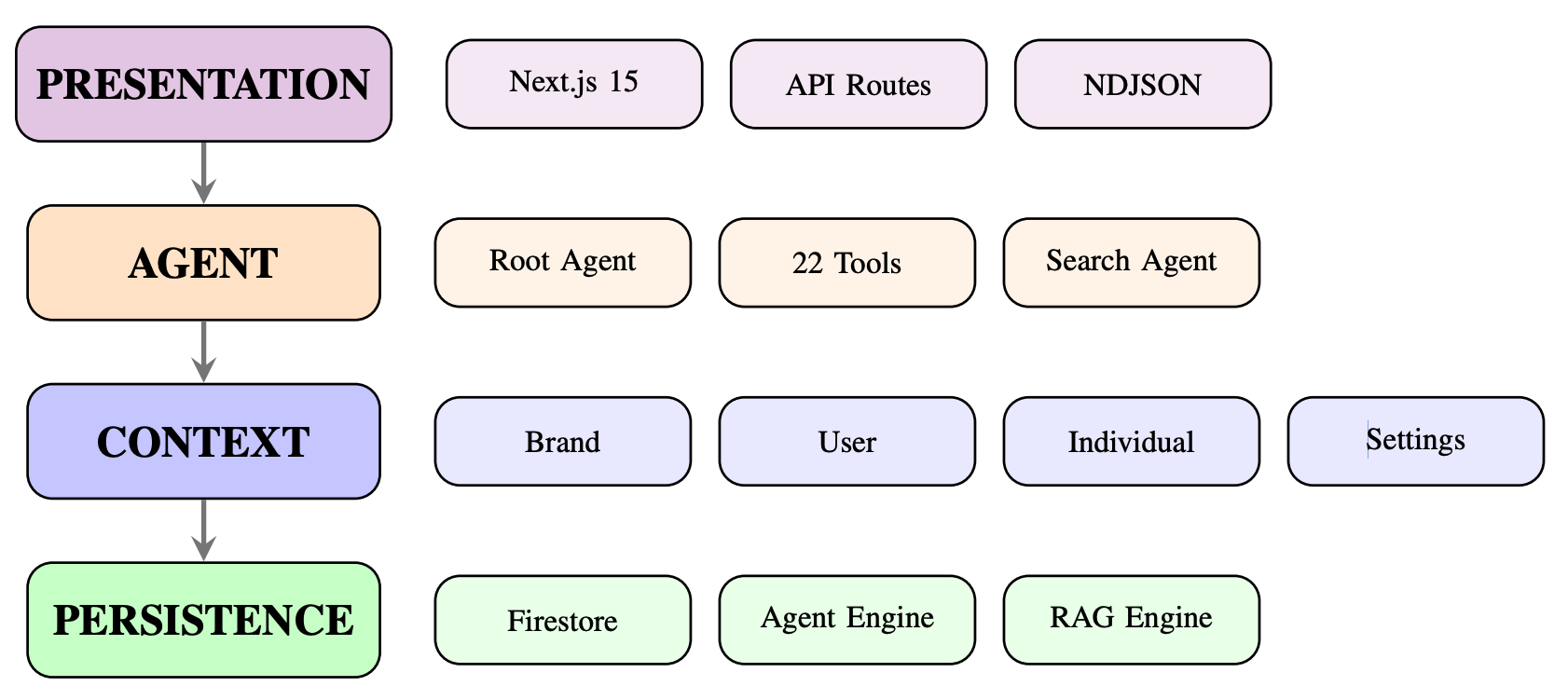
Figure 1. Four-layer architecture: Presentation, Agent, Context, and Persistence layers with vertical context flow.
MOMENTUM is organized as a four-layer stack. The Presentation Layer (Next.js 15 with API Routes) handles user interaction and NDJSON streaming. The Agent Layer hosts a root agent powered by Gemini 2.5 Flash (1M token context window) orchestrating 22 tools across 5 modality categories—Generation (5), Search (4), Memory (2), Media (5), and Team (6)—plus a dedicated search sub-agent that delegates google_search calls to work around Gemini API constraints. The Context Layer manages six hierarchical context layers (Brand, User, Individual, Settings, Media, Team) via Python’s contextvars module, providing thread-safe per-request isolation. The Persistence Layer integrates Firestore, Vertex AI Agent Engine, RAG Engine (text-embedding-005), Cloud Storage, and Discovery Engine.
The system instruction comprises 121 lines with a 10-rule cognitive reasoning framework. Foundation models include Imagen 4.0 for image generation (10 aspect ratios), Veo 3.1 for video generation (5 modes), and Gemini 3 Pro Image for character-consistent editing (up to 14 reference images).
Hierarchical Context Injection
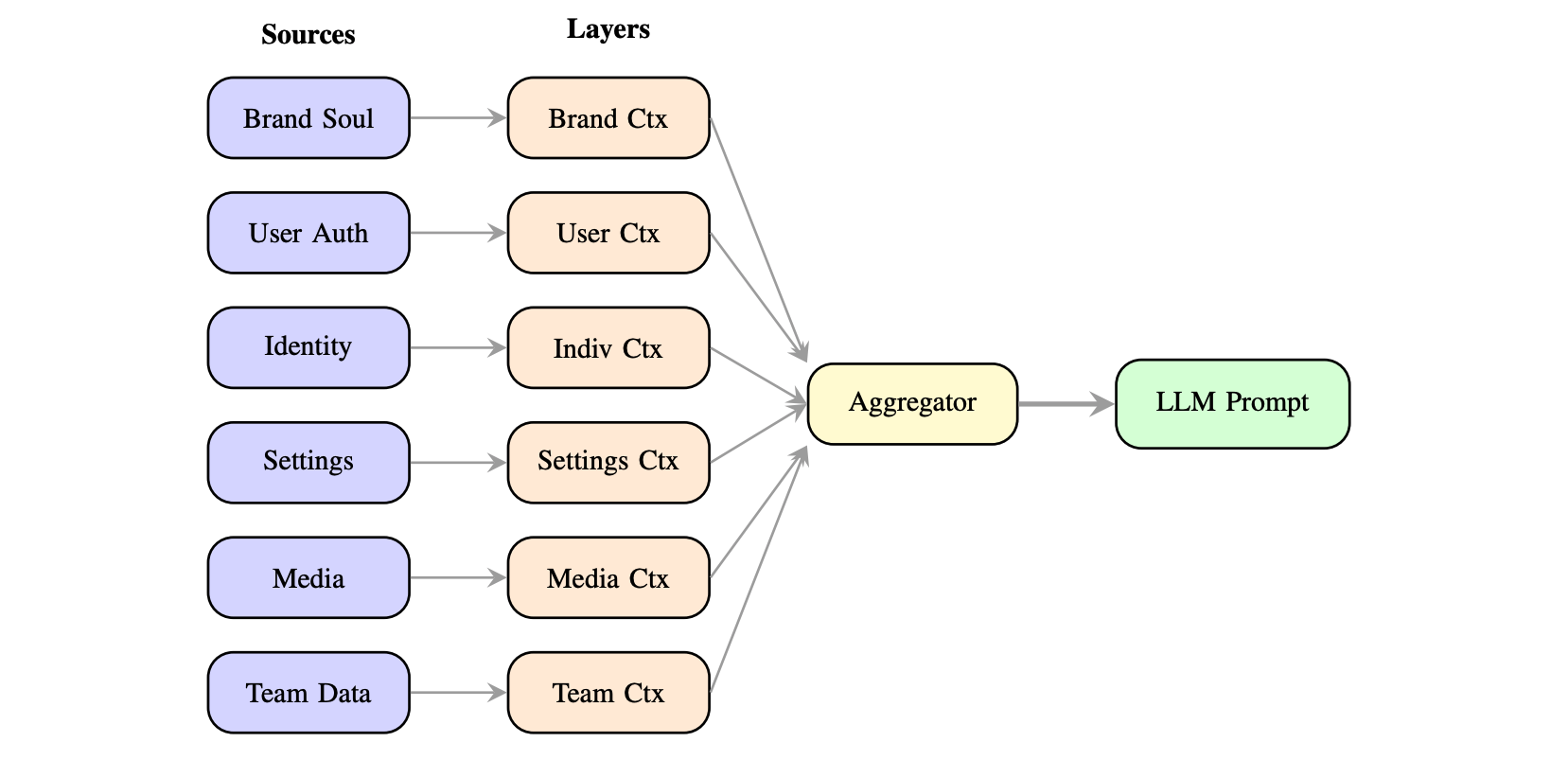
Figure 2. Six context layers flow from heterogeneous sources through extraction into the ContextVar Store, providing O(1) access to all 22 tools simultaneously.
The core innovation of MOMENTUM is its Hierarchical Context Injection mechanism. Existing tool-augmented LLM architectures treat each tool invocation as stateless, causing systematic loss of contextual information across tool boundaries—a phenomenon we term cross-modal context attrition. In conventional sequential pipelines, context available during image generation does not propagate to video synthesis or text generation.
MOMENTUM addresses this through six context layers, each with a defined token budget:
| Layer | Source | Scope | Budget |
|---|---|---|---|
| Brand | Firestore brandSoul | Per-brand | 50K tokens |
| User | Authentication | Per-user | 1K tokens |
| Individual | identities collection | Per-user-brand | 300 tokens |
| Settings | Request payload | Per-request | 500 tokens |
| Media | Attachments | Per-message | Variable |
| Team | Request payload | Per-conversation | 50K tokens |
Using Python’s contextvars module provides thread-safe isolation between concurrent requests, global access without explicit parameter passing, and per-async-task context copies that eliminate race conditions in multi-tenant deployments. Context is set at the start of each API request before agent creation, and all 22 tools import getter functions to access the current context. The result: O(1) constant-time context access—the 15th tool call receives identical contextual richness as the first.
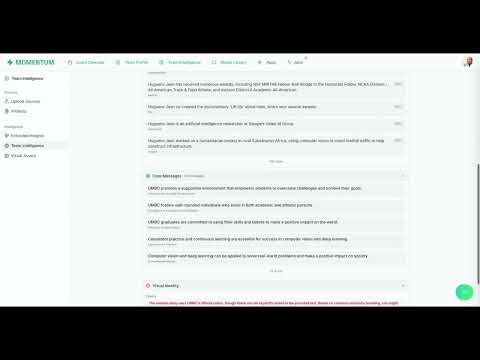
Team Intelligence Pipeline
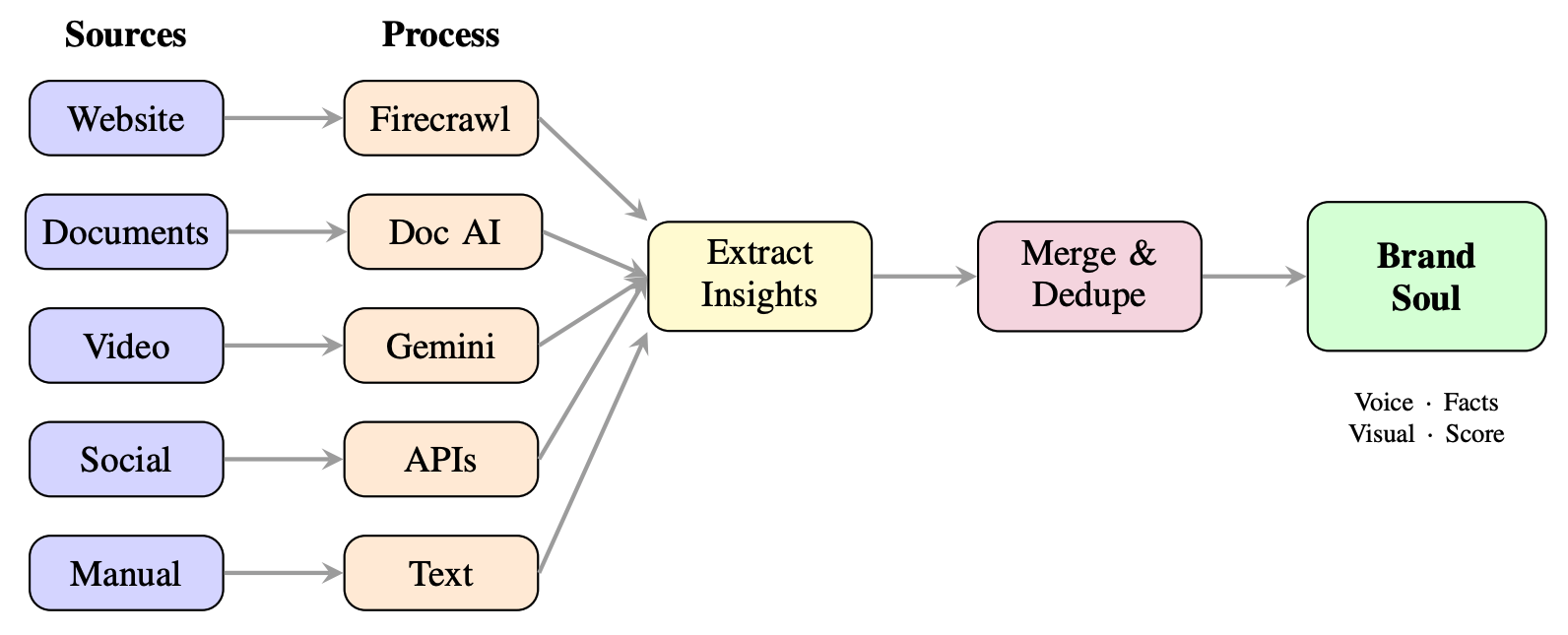
Figure 3. Three-phase pipeline: Artifact Extraction, Brand Soul Synthesis, and Context Retrieval.
The Team Intelligence Pipeline transforms heterogeneous organizational artifacts into a structured “Brand Soul” through three phases:
Phase 1: Artifact Extraction. Six source types (websites via Firecrawl API, PDFs via Document AI, social media, video via Gemini 2.5 Flash Vision, YouTube via Transcript API + Gemini analysis, and manual text input) are processed through modality-specific extractors following a 6-state pipeline (pending → processing → extracting → extracted → approved → published). Each produces an ExtractedInsights object containing voice elements, categorized facts with confidence scores, key messages, and visual identity elements.
Phase 2: Brand Soul Synthesis. Extracted insights merge via confidence-weighted averaging for voice profiles, cosine similarity deduplication (0.85 threshold) for facts, majority voting for visual identity consensus, and composite confidence scoring reflecting extraction quality and artifact coverage.
Phase 3: Context Retrieval. A 10-minute TTL cache balances freshness with performance. The system queries up to 100 artifacts (50 extracted + 50 approved), deduplicates by artifact ID, sorts by recency, and truncates to the token budget (default 1,500 tokens) before injection.
Individual Identity Context Blending
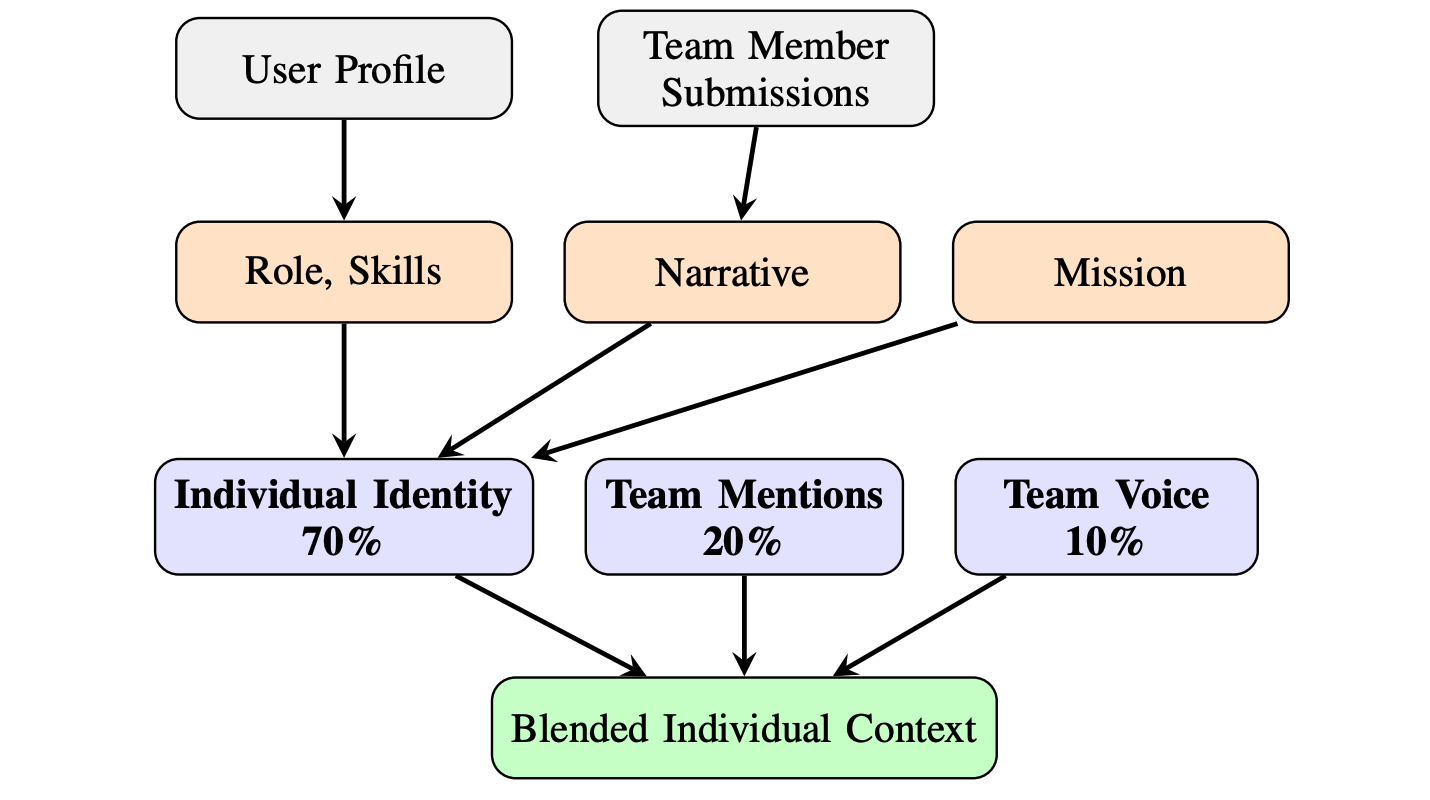
Figure 4. 70/20/10 weighted composition: personal identity, team intelligence mentions, and organizational voice.
Individual Identity Context Blending enables personalized content generation while maintaining organizational consistency. The blending formula is:
Cindividual = 0.70 × Iidentity + 0.20 × Imentions + 0.10 × Ivoice
The 70% individual identity component comprises 9 profile elements: role, narrative, mission, tagline, values, skills, achievements, working style, and testimonials. The 20% team intelligence mentions component filters Brand Soul facts that reference the specific individual. The 10% organizational voice component ensures alignment with the team’s tone and style guidelines. A shorter 5-minute TTL cache reflects the more frequent update cycle of individual profiles compared to organizational Brand Soul.
Dual-Scope Memory Architecture
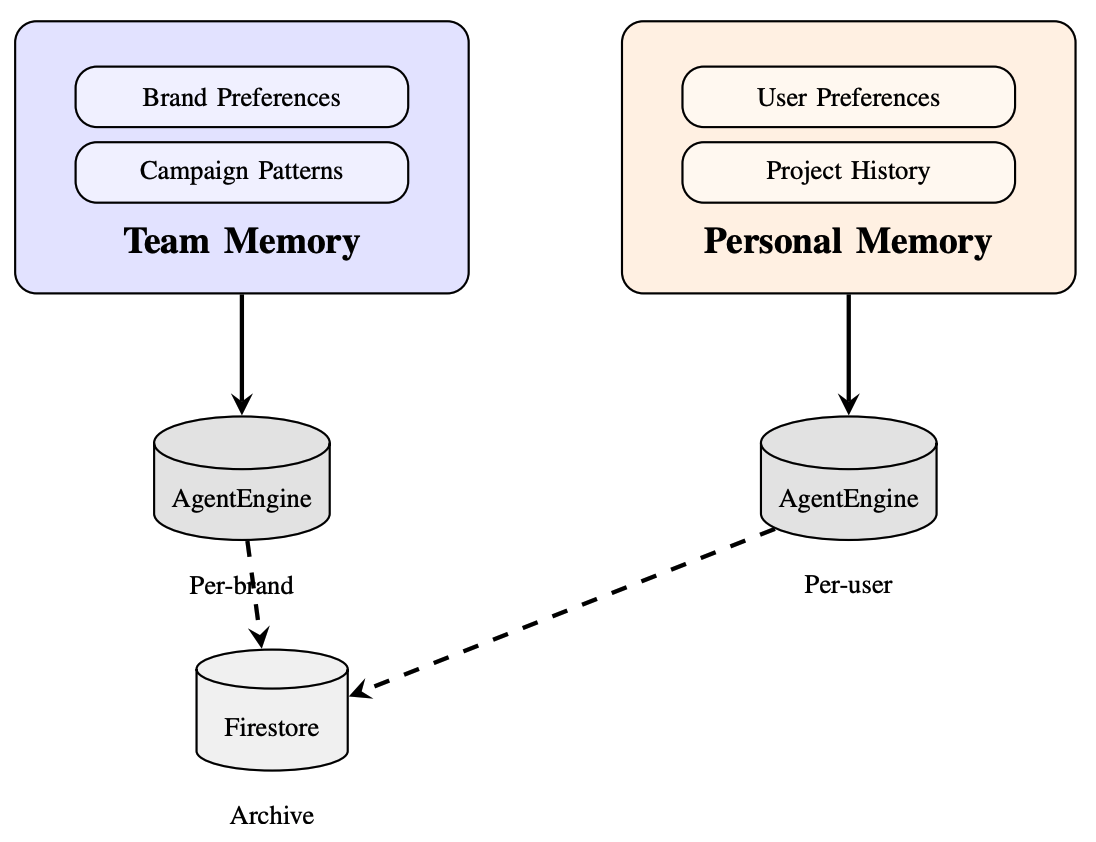
Figure 5. Three-tier memory system: Team Memory (per-brand), Personal Memory (per-user), and Session Memory (ephemeral), with provenance tracking and cascade deletion.
MOMENTUM implements dual-scope persistent memory through Vertex AI Agent Engine with Firestore fallback:
Team Memory (per-brand) stores shared organizational knowledge—brand preferences, campaign patterns, approved styles—accessible by all team members. Personal Memory (per-user) captures individual context including preferences, project history, and terminology. Session Memory provides ephemeral in-conversation storage. Each memory entry links to its source artifact via sourceArtifactId, enabling provenance-tracked cascade deletion: removing an artifact automatically purges all derived memories from both Firestore and Vertex AI. Primary retrieval uses semantic search through Vertex AI Agent Engine with automatic Firestore fallback.
Cross-Team Sponsorship Model
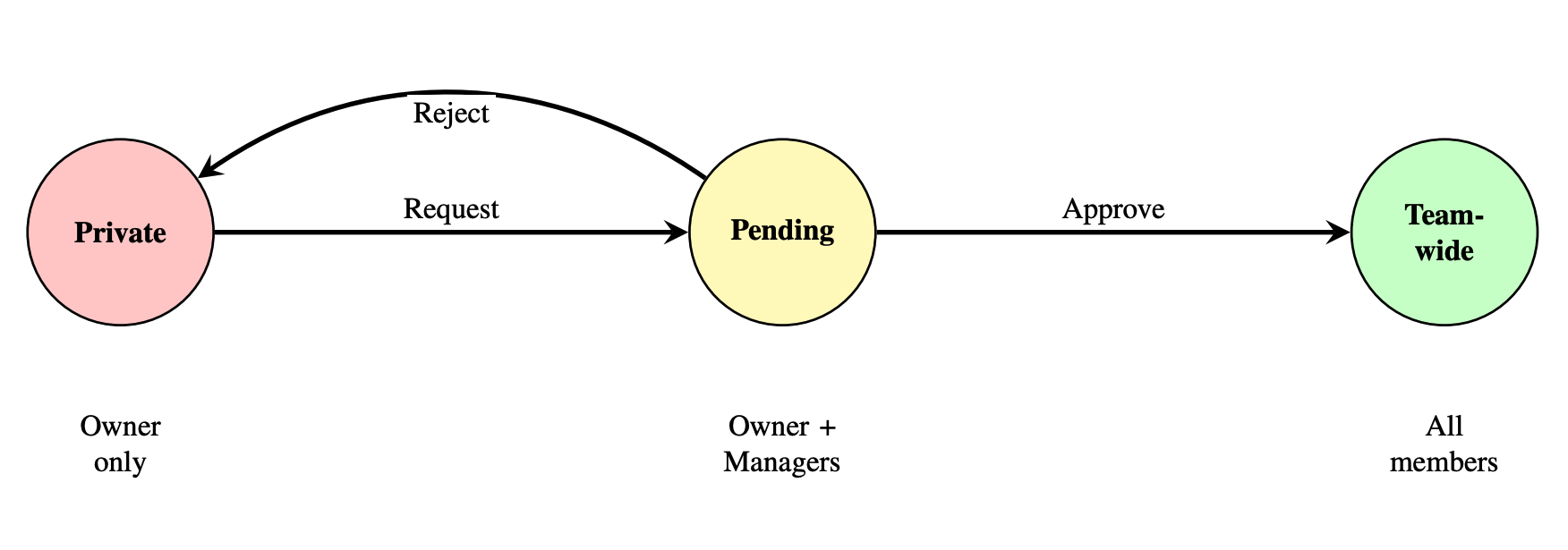
Figure 6. Five-state sponsorship lifecycle: PENDING → ACTIVE / DECLINED / EXPIRED, with ACTIVE → REVOKED. Invitation-based consent model with 7-day window.
The Cross-Team Sponsorship Model enables organizations to observe each other’s Brand Soul and assets through a controlled, unidirectional read-only mechanism. The five-state lifecycle (PENDING, ACTIVE, DECLINED, REVOKED, EXPIRED) uses an invitation-based consent model with a 7-day acceptance window. Active sponsorship grants read-only access to brand profile, Brand Soul, and generated assets, but critically no access to memory banks, editing, or generation capabilities.
A key design principle: sponsorship provides “observation without injection.” Sponsor context is never injected into the sponsored team’s generation pipeline, preventing cross-team context contamination while enabling organizational oversight.
NDJSON Streaming Response Architecture
sequenceDiagram
participant U as User
participant F as Frontend
participant B as Backend (agent.py)
participant A as ADK Agent
participant T as Tool (e.g., generate_image)
U->>F: "Generate a product image"
F->>B: POST /api/agent (NDJSON stream)
B->>A: run_async(message)
A->>T: FunctionCall: generate_image(prompt)
T-->>A: FunctionResponse: {url, format}
Note over B: Intercept FunctionResponse
B-->>F: {"type":"log","content":"Generating image..."}
B-->>F: {"type":"image","data":{"url":"...","format":"png"}}
A-->>B: Final text response
B-->>F: {"type":"final_response","content":"Here's your image..."}
Note over F: Frontend renders image
deterministically from
NDJSON events, NOT
from LLM text markers
Figure 7. Deterministic media display via FunctionResponse interception and typed NDJSON events.
MOMENTUM delivers tool responses through typed NDJSON (newline-delimited JSON) streaming events. When a tool like generate_image returns a FunctionResponse, the backend intercepts it and emits typed events (log, image, video, final_response) directly to the frontend. The frontend renders media deterministically from these structured events rather than parsing LLM-generated text markers—achieving 100% display reliability regardless of how the model phrases its response.
Evaluation Framework
flowchart TB
subgraph Categories["9 TEST CATEGORIES (225+ tests)"]
direction TB
C1["Tool Selection: 90"]
C2["Relevance Detection: 35"]
C3["Memory Persistence: 25"]
C4["Context Flow: 15"]
C5["Multi-Turn: 15"]
C6["Error Recovery: 15"]
C7["Edge Cases: 15"]
C8["Adversarial: 15"]
end
subgraph CoreMetrics["CORE METRICS"]
ACC["Overall Accuracy: 94.0%"]
STAB["Stability Score: 99.26%"]
P1["pass@1: 94.0%"]
P3["pass@3: 99.98%"]
P5["pass@5: 100.0%"]
end
subgraph ContextMetrics["CONTEXT METRICS"]
CP["Context Perplexity"]
CMC["Cross-Modal Coherence
+24.7% to +37.7%"]
end
subgraph Infrastructure["TEST INFRASTRUCTURE"]
FE["Frontend: 2,315 tests
345 files"]
BE["Backend: 539 tests
55 files"]
TOTAL["Total: 2,854 tests
400 files"]
end
Categories --> CoreMetrics
Categories --> ContextMetrics
CoreMetrics --> Infrastructure
style Categories fill:#e8eaf6,stroke:#3f51b5
style CoreMetrics fill:#c8e6c9,stroke:#43a047
style ContextMetrics fill:#fff3e0,stroke:#ff9800
style Infrastructure fill:#f5f5f5,stroke:#9e9e9e
Figure 8. 225+ test cases across 9 categories feeding into core metrics, context metrics, and automated test infrastructure.
Our evaluation synthesizes methodologies from BFCL (tool selection), AgentBench (multi-turn interactions), GAIA (general AI assistant capabilities), LOCOMO (long-context memory), and CLASSic (Cost, Latency, Accuracy, Stability, Security), plus the pass@k stochastic reliability framework. The 225+ test cases span 9 categories with difficulty levels 1–3. See the full benchmarks page for complete methodology, commands, and detailed results.
Cross-Modal Coherence Results
Figure 9. Cross-modal coherence scores across four modality transitions. MOMENTUM achieves +24.7% to +37.7% improvement.
Cross-modal coherence measures how well context propagates when the agent switches between modalities (e.g., from text generation to image generation). Baseline scores reflect a stateless pipeline where each tool invocation loses prior context. MOMENTUM’s hierarchical context injection maintains full Brand Soul, user, and individual identity context across every transition, yielding the largest improvement (+37.7%) in the Text → Video transition—the modality pair most susceptible to context attrition.
Complete Tool Taxonomy
flowchart LR
subgraph Generation["Generation (5)"]
GT[generate_text]
GI["generate_image
Imagen 4.0"]
GV["generate_video
Veo 3.1"]
AI["analyze_image
Gemini Vision"]
NB["nano_banana
gemini-3-pro-image"]
end
subgraph Search["Search (4)"]
WSA["web_search_agent
Sub-agent"]
CW["crawl_website
Firecrawl"]
SML["search_media_library
Discovery Engine"]
QBD["query_brand_documents
RAG Engine"]
end
subgraph Memory["Memory (2)"]
SM["save_memory
Vertex AI + Firestore"]
RM["recall_memory
Semantic search"]
end
subgraph Media["Media (5)"]
SI[search_images]
SV[search_videos]
STM[search_team_media]
FSM[find_similar_media]
SYV[search_youtube_videos]
end
subgraph Team["Team (6)"]
SDN[suggest_domain_names]
CTS[create_team_strategy]
PW[plan_website]
DLC[design_logo_concepts]
CE[create_event]
PYV[process_youtube_video]
end
style Generation fill:#ffcdd2,stroke:#e53935
style Search fill:#c8e6c9,stroke:#43a047
style Memory fill:#bbdefb,stroke:#1e88e5
style Media fill:#fff9c4,stroke:#fdd835
style Team fill:#e1bee7,stroke:#8e24aa
Figure 10. All 22 tools organized by modality: Generation (5), Search (4), Memory (2), Media (5), Team (6).
Every tool in the taxonomy receives the full six-layer context stack via contextvars. The agent model (Gemini 2.5 Flash) selects tools based on the user’s intent, and each tool’s output flows back as a FunctionResponse that the backend intercepts for NDJSON streaming. Tool selection achieves 100% accuracy on the 60-test tool selection benchmark (n=15 per tool category).
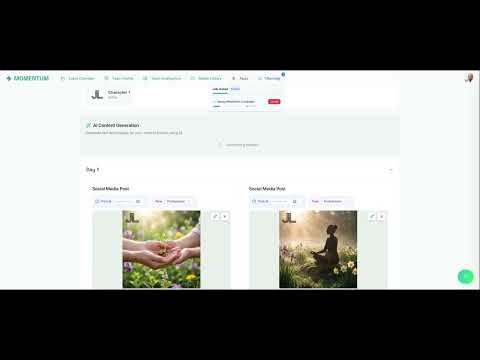
Demo: Multi-Modal Content Generation
This demo shows MOMENTUM generating text copy, product images (Imagen 4.0), and a campaign video (Veo 3.1) within a single conversation—all maintaining the Brand Soul’s voice, visual identity, and messaging framework throughout.
Demo: Team Intelligence in Action
The Team Intelligence Pipeline processes a company website through Firecrawl, extracts voice elements and facts with confidence scores, synthesizes a Brand Soul, and immediately uses that context to generate on-brand content—demonstrating the full extraction → synthesis → generation loop.
Demo: Dynamic Generative Profile Sections
MOMENTUM’s profile system goes beyond static bios. Each profile is composed of dynamic, generative sections—role, narrative, mission, tagline, values, skills, achievements, working style, and testimonials—that the AI can remix and recombine on demand. When a team member updates their profile, every downstream generation (ad copy, email campaigns, social posts, press releases) automatically reflects the change. Because profiles are collaborative—managers shape organizational voice, contributors refine their individual identity—the 70/20/10 weighted blending formula produces text that is simultaneously personal, team-aware, and brand-consistent. This is not template-based generation: the agent synthesizes structured profile elements with Brand Soul context and campaign intent to produce original, contextually faithful copy for any use case, from investor decks to product launches.
Demo: Memory Persistence Across Sessions
MOMENTUM’s dual-scope memory banks persist across sessions. This demo saves brand preferences and campaign decisions, then starts a fresh conversation where the agent recalls those facts via semantic search through Vertex AI Agent Engine—proving that organizational knowledge survives session boundaries.
Demo: Character Consistency (Nano Banana)
Using Gemini’s native image generation model (gemini-3-pro-image-preview), Nano Banana maintains character consistency across multiple generated assets. This demo shows the same brand logo appearing in different contexts—product packaging, social media posts, event materials—while preserving visual identity through reference image conditioning and full Brand Soul visual context injection.
Demo: Real-Time NDJSON Streaming
MOMENTUM streams responses as they generate: text tokens flow in real-time while images and videos appear inline as each tool completes. The NDJSON protocol enables deterministic, interleaved media display independent of LLM text generation—eliminating the common failure mode where generated media appears at the wrong position or not at all.
Demo: Vertex AI Search & Vision Analysis
MOMENTUM leverages Vertex AI Search for semantic media retrieval across the team’s multimodal library. This demo walks through the full pipeline: running AI Vision Analysis on uploaded images and videos to extract descriptions, keywords, and categories; indexing the enriched metadata into a Vertex AI Search datastore; and then asking the agent natural language queries like “find images with blue backgrounds” that return ranked results with relevance scores.
Demo: Vertex AI RAG Engine
MOMENTUM integrates Vertex AI RAG Engine for grounded question answering over team documents. This demo shows uploading brand guidelines, strategy decks, and reference documents; indexing them into a RAG corpus; and then querying the agent with questions that retrieve relevant passages and generate grounded, citation-backed responses—ensuring the agent’s answers are rooted in the team’s own source material.
Results
Overall Evaluation
| Metric | Result |
|---|---|
| Overall Accuracy | 94.0% |
| Stability Score | 99.26% |
| pass@1 | 94.0% |
| pass@3 | 99.98% |
| pass@5 | 100.0% |
| Tool Selection (n=60) | 100.0% |
Latency Distribution
| Percentile | Latency |
|---|---|
| Average | 6,428 ms |
| P50 (Median) | 3,437 ms |
| P95 | 22,404 ms |
| P99 | 29,874 ms |
Ablation Study: Context Layer Contributions
| Configuration | Accuracy | Impact |
|---|---|---|
| Full System (all 6 layers) | 94.0% | — |
| − Brand Soul | 81.2% | −12.8% |
| − User Memory | 89.4% | −4.6% |
| − Settings Context | 91.7% | −2.3% |
| − All Context | 72.3% | −21.7% |
Key finding: Context layers exhibit synergistic interactions. The combined removal impact (−21.7%) exceeds the sum of individual removals (−19.7%), demonstrating that layers amplify each other’s effectiveness.
Cost Analysis (Gemini 2.5 Flash)
| Metric | Value |
|---|---|
| Total Tokens (100-test suite) | 31,712 |
| Estimated Cost | $0.0052 |
| Cost per Test | ~$0.00005 |
For complete benchmark methodology, all test categories with examples, runner commands, and per-tool breakdowns, see the full benchmarks page.
Citation
Acknowledgements
We thank the Google Cloud AI team for Vertex AI services, the ADK team for the foundational agent framework, and the Gemini, Imagen, and Veo teams for the foundation models that power MOMENTUM’s generation capabilities.